Is the future of computing truly quantum? And did Google’s latest chip really perform across multiple universes?
In a groundbreaking announcement, Google Quantum AI unveiled “Willow”, its new quantum chip that’s pushing boundaries—and possibly crossing into parallel universes. While the headlines are buzzy, let’s break down what’s really happening and what this means for the future of quantum tech, patent strategy, and commercialization.
Quantum Supremacy—Again?
According to Hartmut Neven, the founder of Google Quantum AI, the Willow chip completed a benchmark quantum computation in under five minutes—a task that would reportedly take a supercomputer 10 septillion years.
“Willow performed a standard benchmark computation in under five minutes that would take one of today’s fastest supercomputers 10 septillion (10²⁵) years.”
That’s longer than the age of the universe.
But here’s the catch: the task itself has no real-world application. It’s designed to demonstrate quantum supremacy, not utility.

What Did Willow Actually Do?
The computation in question was to generate a random distribution, a task that’s notoriously difficult for classical computers. However, this is the same calculation that Google used in its 2019 quantum supremacy claim—a claim that was contested by IBM and later replicated using classical systems.
So, while Willow’s error reduction using more qubits is impressive, its commercial relevance is still uncertain.
Quantum Mechanics, Patents & the Multiverse?
Tucked in Google’s announcement was a reference to the Many Worlds Interpretation of quantum mechanics. Neven suggested that the chip’s performance “lends credence to the notion that quantum computation occurs in many parallel universes.”
This is tied to David Deutsch’s theory of quantum parallelism, where computation occurs across branches of the multiverse, rather than collapsing into one outcome. While fascinating, this remains speculative—and it has no impact on how patents are filed or enforced today.
Still, these bold claims reflect a trend: quantum computing is evolving, and IP frameworks must evolve with it.
Real Challenges: Quantum ≠ Practical (Yet)
Despite the hype, quantum computing remains experimental:
- Google’s global challenge offering $5 million to find a practical use case for quantum computing still stands.
- Current quantum algorithms are narrow, and error rates remain a bottleneck.
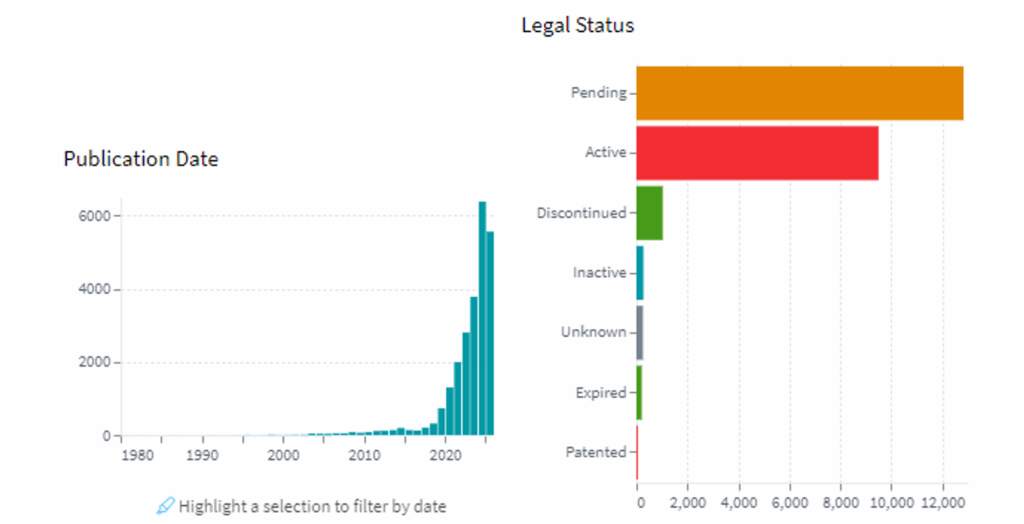
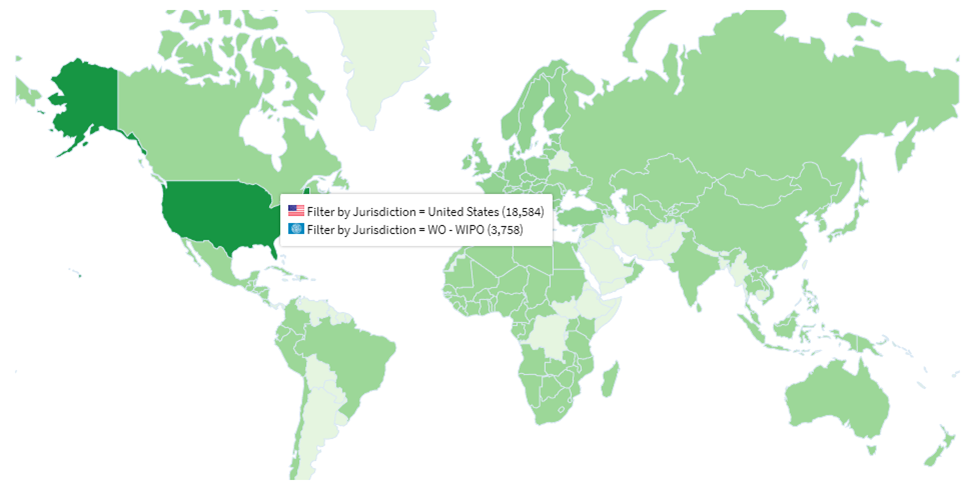
- The IP ecosystem around quantum tech is nascent, and patent clarity is crucial for future commercialization.
This is why companies and investors need to keep a close eye on not just quantum announcements, but also standardization efforts, licensing frameworks, and IP protection mechanisms.

How Do Quantum Computers Actually Work?
Let’s simplify:
- Classical computers process bits (0s and 1s).
- Quantum computers rely on qubits, which use superposition and entanglement.
- They use interference patterns to solve complex problems, theoretically faster than any classical system.
However, the actual power lies in building error-resilient, scalable quantum chips—and protecting these innovations with well-structured patents.
Why This Matters for Innovators & IP Strategy
- Quantum computing is expected to disrupt multiple industries: cybersecurity, pharma, materials science, and logistics.
- As we inch closer to quantum advantage, companies must act now to evaluate, patent, and license their innovations.
- At Intellect Partners, we help clients navigate the complex patent landscapes around quantum and emerging technologies.
Whether it’s freedom-to-operate analysis, claim charting, or licensing strategy, our team ensures your IP portfolio is aligned with tech frontiers.
Final Thoughts: Buzz vs Reality
While it’s fun to speculate about quantum computers tapping into alternate realities, what truly matters is building commercially useful, reliable, and scalable quantum systems—and securing them with strong IP protection.
Google’s Willow chip is a leap forward, but we’re still a long road away from widespread adoption. Until then, innovators and tech leaders must focus on building value—one patent at a time.
Interested in understanding how quantum tech intersects with IP?
Contact Intellect Partners for a consultation on IP strategies for quantum and other next-gen technologies.