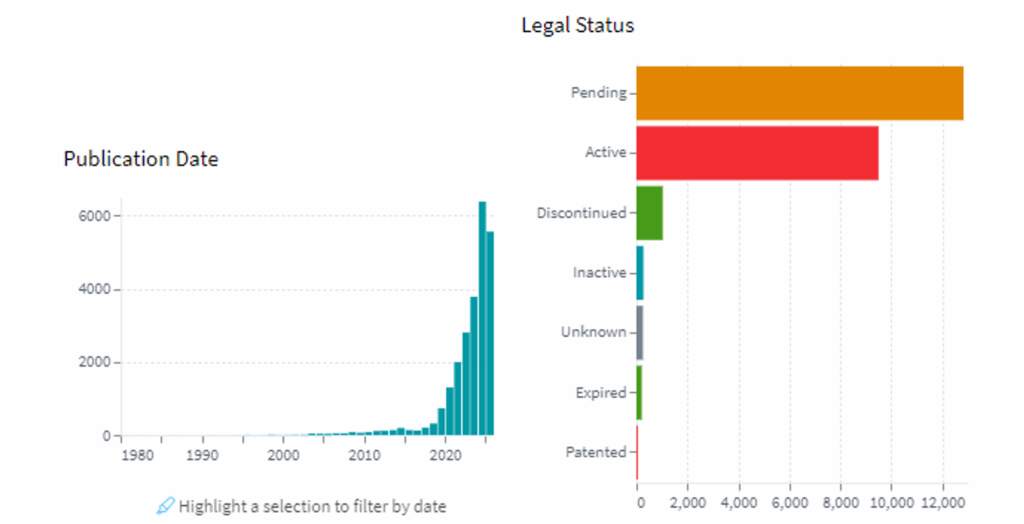
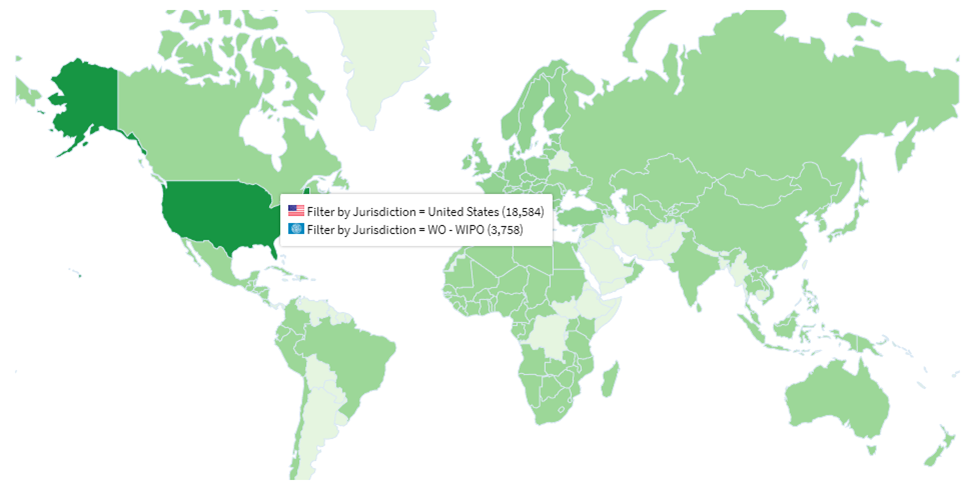
In the rapidly evolving landscape of Artificial Intelligence, the pursuit of groundbreaking innovation often intersects with the critical need for transparency and trust. A recent patent application from tech giant Microsoft, focusing on a “generative AI for explainable AI,” underscores this crucial intersection, highlighting a significant step towards demystifying how AI models arrive at their conclusions. For businesses navigating the complexities of AI adoption, understanding the implications of such intellectual property is paramount.
Two Minds Are Better Than One: A Novel Approach to AI Explanations
Microsoft’s innovative approach posits that the best way to understand one generative AI model is to employ another. This patent application reveals a system designed to illuminate the inner workings of machine learning outputs, providing users with much-needed clarity on the ‘why’ behind an AI’s decision.
Imagine an AI system being queried: “Why was this loan approved (or denied)?” Microsoft’s proposed technology doesn’t just offer a single answer. Instead, it meticulously analyzes the input data (the loan application), alongside relevant historical data, user preferences, past explanations, and even subject matter expertise. This comprehensive analysis generates multiple potential explanations for the AI’s output.
But the innovation doesn’t stop there. Crucially, the system then leverages a second generative AI model to rank these potential explanations based on their relevance and clarity. This multi-layered approach aims to deliver not just an explanation, but the most pertinent explanation, fostering genuine understanding and confidence in AI-driven outcomes.
The Imperative of Explainable AI (XAI) in Enterprise Adoption
As Microsoft succinctly states in its filing, Explainable AI (XAI) “helps the system to be more transparent and interpretable to the user, and also helps troubleshooting of the AI system to be performed.” This statement resonates deeply with the challenges faced by enterprises deploying AI today.
The race to build and deploy advanced AI is undeniable, yet persistent issues like algorithmic bias and “hallucinations” (AI generating false information) continue to erode trust and pose significant liability risks. Without robust monitoring and a clear understanding of AI decision-making processes, the promise of AI can quickly turn into a peril.
This is precisely why responsible AI frameworks are gaining traction across industries. A recent McKinsey report highlighted this trend, revealing that a majority of surveyed companies are committing substantial investments – over $1 million – into responsible AI initiatives. The benefits are clear: enhanced consumer trust, fortified brand reputation, and a measurable reduction in costly AI-related incidents.
Protecting Your AI Innovations: The Role of Intellectual Property
For a patent intellectual property firm, Microsoft’s move is a powerful signal. As companies like Microsoft push the boundaries of AI, protecting the underlying methodologies and novel applications becomes critical. Patents like this one not only secure a competitive advantage in the burgeoning AI market but also provide a shield against potential liabilities that arise from AI’s complex and sometimes opaque nature.
By actively researching and patenting explainable and responsible AI technologies, Microsoft is not just aiming for a lead in the “AI race”; it’s strategically building a foundation of trust and accountability. This proactive approach to intellectual property in AI, particularly around explainability, could significantly bolster a company’s reputation and safeguard its innovations against future challenges.
For businesses developing or deploying AI, understanding the nuances of AI patents and the strategic importance of explainability is no longer optional – it’s a fundamental pillar of responsible and successful AI integration.
Generative AI is having a moment. If you have asked a curious question into the digital ether, whether you are plugged into tech, a business owner, a student, or just someone navigating the worldwide web, you have probably encountered generative AI tools such as OpenAI’s ChatGPT, Google’s Gemini, Meta’s LLaMA, or Microsoft’s Copilot. These systems can write essays, create images, write emails, help with coding, and even write legal documents. The enthusiasm around these services is dizzying—imagining infinite creativity and productivity, as well as having every bit of human knowledge at your fingertips.
However, amidst the digital gold rush, cracks are starting to appear. These tools, often remarkable, still cannot be trusted. They hallucinate facts, misunderstand questions, misinterpret context, occasionally deliver answers that are completely incorrect, and sometimes, even downright dangerous. Additionally, as more websites, applications, and platforms begin to rely on generative AI for everyday features, it feels like we are slowly staging the entire internet into beta again. We’ve entered a wild west of unpredictability and experimentation (not everything works as we think it should).
What Exactly Are the Reliability Issues?
To identify the source of the problems, we have to understand a little about how generative AI operates. These models are trained on extensive databases, essentially the public stretch of the entire internet, through something called ‘unsupervised learning,’ with the aim of predicting the next word in a sequence. That’s it. There is no real understanding, logic, or knowledge of facts behind their answers.
This means even the best of systems can produce errors such as:
Hallucinations: Confidently stating something as fact when it is false.
Bias and offensive material: Reflecting harmful stereotypes contained in training data.
Inconsistency: Providing different answers to the same question based on how the question is posed.
Context fade: Losing track of long conversations and understanding of subtle changes in context.
Overconfidence: Presenting guesses in an authoritative tone, which leads users to trust incorrect information.
In the case of a user asking a chatbot for legal advice, they may receive fabricated case law. A student using AI for historical facts could be misled by fictitious quotes (i.e., the user takes the output as fact). Even a technologically savvy user may fall victim to errors if they do not fact-check the outcomes.
Real-World Examples of AI Misfires
The news just keeps rolling:
Google’s AI Overviews, which were supposed to enhance search, suggested that users eat rocks and put glue in their pizza sauce, were predicated on misunderstood or satirical sources.
Air Canada’s chatbot advertised a non-existent refund policy, and the company was forced to abide by it when challenged in court.
A New York lawyer had ChatGPT draft a legal brief that cited total fabrication of court cases, which eventually made it to a hearing, and the judge sanctioned him, and the story went viral.
Bing’s chatbot (early version) was reported to be aggressive or emotionally manipulating users in long conversations.
These are not just bugs; these are symptoms of a substantial reliability problem in the generative AI architecture.
Why Is This Happening?
Generative AI is founded on the notion that it doesn’t “know” anything. It neither checks facts, discovers truths, consults other sources, nor even questions its outputs. It simply generates output based on mathematical data patterns. This causes a few critical issues:
1. No Ground Truth
AI systems don’t “know” what a fact is. They only generate plausible text outputs, not facts. Even if training data was rigid facts, it could erase that information, or cross data facts together, especially if the user inputs a narrow, specialty, or complex request/input.
2. Training Data Has Errors
If you give an AI a set of training data from the internet, it includes all of the errors, biases, and nonsensical knowledge. Satire, misinformation, tiny errors, etc., are all equal verbal inputs.
3. Models Don’t Know Anything About Current Knowledge
Most models won’t provide feedback on current knowledge after their training, and therefore don’t know what is currently happening in the world. Some like ChatGPT even augment knowledge with a live search, but most do not. Most likely, if the AI’s output left knowledge before it collected knowledge, then basic current event questions can turn badly.
4. Models Have No Accountability
An AI system will not say, “I’m wrong” unless you make it. The system will not tell you, “I’m guessing.” The next output will always be a flat, confident, polished output, which is potentially dangerous and misleading.
Can Reliability Be Improved?
Yes—but it will take more than simply data and computing power. This is what companies and researchers are doing:
1. RAG (Retrieval-Augmented Generation)
Rather than relying solely on the AI’s knowledge from its training database, RAG systems create systems that go out to external databases or the web to retrieve information in real time before generating the answer based on the previous relevant information. This can help to eliminate some hallucinations and give a level of confidence around facts.
2. Model Alignment and Guardrails
Many companies such as OpenAI, Anthropic, and Google are putting massive resources into making AI outputs safer and more reliable by applying alignment approaches, reinforcement learning from human feedback (RLHF), and built-in moderation systems.
3. Domain-Specific Models
General all-purpose AI may never be fully competent across entire domains. However, focused AIs trained on specific fields such as law, medicine, or engineering can deliver output with much higher reliability.
4. Fact-Checking Layers
Some startups and research organizations are developing AI layers that double-check the output of another model—think an “AI proofreader” that seeks to validate claims, citations, and logical soundness.
What Can Users Do Right Now?
Users must be cautious and skeptical when using generative tools, such as AI, until AI becomes fully reliable.
Here are some best practices:
Always validate AI-generated content, especially in sensitive situations (e.g., health care, finance, or law).
Ask follow-up questions to clarify the AI’s reasoning or solicit its citations.
Work with trusted platforms that offer transparency, disclaimers, or access to source links.
Think of AI as a collaborator, not an authority. AI is an effective tool, but it is not an expert replacement.
Why This Affects the Whole Internet
Generative AI is rapidly becoming the infrastructure of digital experiences—be it in search engines or help desks, creative tools or education platforms. Companies are hurrying to integrate AI capabilities, often the model is often not production-ready when it is deployed.
This creates a paradox; the more we lean into AI, the more we expose our user/users to its shortcomings. And if these issues are never addressed, it can lead to:
A decrease in public trust in digital platforms.
Misinformation at scale.
Legal liabilities and regulatory push-back.
Furthering the knowledge gap for the less-savvy user who assumes that whatever is generated is always accurate.
Conclusion
Generative AI is not broken; it’s simply not fully baked. The tech sector is still figuring out how to augment generative models in ways that are trustworthy, transparent, and safe. These are necessary growing pains in what is potentially one of the most significant technological shifts of modern times. It is time for users, creators, and organizations to come to terms with the fact that it is not a mature technology yet. The shine of AI-generated content glosses over the brittleness behind the curtain.
Until generative AI systems can reliably distinguish fact from fiction, we’re all in a beta version of the future—and it’s on all of us to proceed cautiously, ask questions, and demand better.
Introduction: The Impact of NLP and Conversational AI on Modern Technology
Natural Language Processing (NLP) and Conversational AI have evolved from niche research areas to transformative forces across industries. NLP enables machines to understand, interpret, and generate human language, while Conversational AI, a subfield of NLP, empowers systems to interact with people in ways that feel intuitive and human-like. These technologies are behind virtual assistants like Siri and Alexa, customer service chatbots, and even translation apps.
With this rise in application, the patent landscape for NLP and conversational AI has seen significant growth. Organizations are racing to secure intellectual property (IP) for innovations that span from core algorithms to advanced systems designed for specific use cases like healthcare, finance, and smart devices. In this post, we’ll explore foundational NLP techniques, the major components of Conversational AI, the role of patents, and emerging trends in this dynamic field.
Foundations of NLP: Core Components and Techniques
1. Text Preprocessing Techniques
NLP begins with converting raw text data into structured forms suitable for machine learning models, a process known as preprocessing. This stage involves several steps:
Tokenization: Splitting text into smaller units, or “tokens,” like words or sentences.
Lemmatization and Stemming: Reducing words to their root forms, which helps generalize the data.
Stop-word Removal: Eliminating common words like “the,” “is,” or “and,” which typically don’t add much meaning.
2. Machine Learning Models in NLP
NLP tasks rely heavily on machine learning models, which fall into two main categories: supervised and unsupervised learning.
Supervised Learning: Involves labeled data where each text sample has a known outcome, such as classifying a customer review as positive or negative.
Unsupervised Learning: Uses unlabeled data to identify hidden patterns, such as topic modeling to categorize research articles.
3. Advanced NLP Models: Transformers and Large Language Models (LLMs)
The advent of transformer models, like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), marked a breakthrough in NLP accuracy. Transformers use self-attention mechanisms to focus on relevant parts of input sequences, allowing them to generate contextually accurate responses.
Conversational AI: Components of Engaging, Interactive Systems
1. Types of Conversational AI Systems
Conversational AI systems can be broadly divided into rule-based systems and AI-driven systems:
Rule-based Systems: Follow pre-set rules for each user input. These systems are straightforward but lack the adaptability of AI-driven models.
AI-driven Systems: Use NLP to interpret user intent, enabling them to handle complex interactions. They are used in applications like customer support bots and virtual assistants.
2. Components of Conversational AI
Natural Language Understanding (NLU)
NLU identifies the user’s intent and extracts relevant information, known as entities, from their input. For example, in a sentence like “Book a flight to Paris next Tuesday,” NLU would recognize “flight,” “Paris,” and “next Tuesday” as key entities.
Natural Language Generation (NLG)
NLG enables the system to generate responses, making the conversation feel natural. The system uses grammar rules or machine learning models to convert structured data back into human language.
Speech Recognition and Synthesis
Speech recognition and synthesis transform spoken language into text and vice versa, a critical component for virtual assistants.
The Role of Patents in NLP and Conversational AI
1. Types of Patents in NLP and Conversational AI
Patents cover a range of innovations in NLP and Conversational AI. Here are a few primary categories:
Core NLP Techniques: Algorithms for tokenization, named entity recognition, and sentiment analysis.
Conversational AI Frameworks: Patent protections for multi-layered conversation flows, intent recognition systems, and dialog management strategies.
Hardware Integration: Patents that focus on integrating NLP and conversational AI with specific devices, such as IoT devices or smart speakers.
2. Noteworthy NLP Patents and Holders
Leading companies like Google, Microsoft, and Amazon hold influential patents in NLP. For instance:
Google’s BERT Model Patent: Covers innovative aspects of the transformer model architecture.
Amazon’s Alexa Patents: Encompass a wide range of speech processing and conversational flow technologies.
3. Regional Patent Trends and Challenges
The U.S., China, and Japan are major hotspots for NLP and conversational AI patents, with each region presenting unique challenges around data privacy, patent eligibility, and regulatory standards.
Emerging Trends and Advanced Patent Areas in NLP and Conversational AI
1. Multilingual NLP
With globalization, multilingual NLP is gaining traction, allowing companies to create applications that work across languages and regions. Patents in this area cover universal language models and techniques for efficient language translation.
2. Emotion and Sentiment Analysis
Emotion analysis allows conversational AI to recognize user emotions, making interactions more empathetic. This is particularly useful in customer service and mental health applications, where an understanding of sentiment can greatly improve user experience.
3. Domain-Specific NLP Applications
NLP models tailored for specialized domains—like healthcare, law, and finance—are rapidly emerging. Patents in these areas protect domain-specific applications such as medical diagnostic tools or financial analysis systems.
Challenges in Patenting NLP and Conversational AI
1. Patent Eligibility and Scope
One of the challenges in NLP patenting is defining patentable boundaries. Patenting algorithms and conversational flows often faces scrutiny for being abstract ideas rather than tangible inventions.
2. Ethical Concerns and Bias
AI models can inherit biases from training data, which is a concern for patent holders and developers alike. Patents must address the risk of biased NLP systems, as these can lead to unintentional exclusion or misrepresentation.
Future Directions for NLP and Conversational AI Patents
1. Explainable AI and Transparency
Explainable AI is essential in sectors like healthcare, finance, and law, where decisions need to be interpretable. Patents are emerging for NLP models that include mechanisms for transparency in decision-making.
2. Real-Time Processing with Edge Computing
Real-time conversational AI, enabled by edge computing, is reducing latency and enhancing privacy by performing data processing on local devices rather than cloud servers.
Conclusion
The rise of NLP and conversational AI patents illustrates the importance of protecting IP in this rapidly evolving field. Innovations in multilingual NLP, emotion recognition, domain-specific applications, and explainable AI continue to shape the landscape. As conversational AI becomes increasingly integral to daily life, patent holders are poised to set the standards for future advancements in technology.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.