San Francisco-based intellectual property startup Fearn has announced the completion of a $5.5 million seed funding round to expand its AI-native patent drafting platform.
The round was led by Kindred Ventures, with participation from Andreessen Horowitz’s a16z speedrun startup accelerator, Designer Fund, and Essence VC. Prior to this institutional round, the company operated via founder self-funding.
The Founders and the Logic of Automation
Fearn was founded in 2025 by CEO Han Kim and CTO Angela Gao, who met as graduate students at Caltech. The platform’s architectural focus stems directly from the co-founders’ specialized backgrounds:
Han Kim: Previously prosecuted patent applications across software, life sciences, and mechanical arts as a scientific analyst at Morrison & Foerster, while researching bio-inspired neural algorithms during his Ph.D. track at Caltech.
Angela Gao: Completed a Ph.D. in computing and mathematical sciences at Caltech, specializing in physics-aligned generative models, alongside previous model development work at Google Research.
Kim noted that his experience in Big Law highlighted systemic inefficiencies in the traditional patent pipeline, which is frequently slow, cost-prohibitive, and anxiety-inducing for engineers worried about technical details being misinterpreted.
“I noticed a lot of the tasks I was doing could be automatable, but obviously I couldn’t automate them. You’re not really allowed to in those sorts of settings and environments,” Kim stated, highlighting the strict procedural friction within traditional law firms that inspired him to build an external automation solution.
How the Multi-Model Stack Works
Unlike general-purpose generative AI tools or simple API wrappers, Fearn is built from the ground up as a fully data-sovereign, AI-native platform. The coordinates a specialized multi-model stack:
Bespoke Model Ensemble: The platform utilizes dozens of hypercompact, specialized models, combining proprietary code, fine-tuned open-source models, and symbolic non-LLM systems built from scratch.
Data Sovereignty: Fearn hosts 100% of its own model stack internally. It makes zero application programming interface (API) calls to third-party model developers, completely removing the public-disclosure and data-egress risks that typically restrict enterprise IP teams from leveraging generative AI.
Hallucination Resistance: By training its custom architectures on highly curated, hand-corrected, and hand-labeled intellectual property datasets, Fearn creates audit trails engineered to guarantee compliance with patent office requirements and eliminate the factual errors common in large language models.
Once the application and automated labeled figures are ready, corporate research teams or solo inventors can choose to file the paperwork independently or hand it off to external counsel for final strategic review. Fearn charges a flat, predictable fee of $2,000 per patent draft, cutting traditional preparation timelines down significantly.
Future Plans and the Legal Tech Boom
With a lean team of fewer than 10 people, Fearn plans to deploy the capital injection primarily toward technical hiring, infrastructure expansion, and offsetting computational overhead.
Looking forward, the company intends to scale its features to assist inventors throughout the entire end-to-end patent prosecution lifestyle. This includes expanding automated systems to handle office action responses and any procedural workflow tied directly to a U.S. Patent and Trademark Office (USPTO) registration number.
Fearn’s successful seed round emphasizes an accelerating streak of legal tech investments by Andreessen Horowitz. The firm’s recent IP and legal portfolio expansion includes:
Leading patent automation startup Stilta’s seed round.
Anchoring multiple massive funding rounds for legal AI platform Harvey.
Backing litigation-focused developer Eve across two distinct rounds.
Leading the pre-seed round for communication security provider ZeroDrift.
I remember the first time I really thought about data in use. I was reading a patent application for a healthcare analytics platform, and the diagram showed three neat padlocks: one for data at rest, one for data in transit, and … nothing for the middle step. The middle step was where the server actually crunched the numbers. That gap always bothered me. Why are we comfortable decrypting sensitive data just to do math on it?
Confidential computing is, at heart, the answer to that question. If you’ve been following security trends, you’ve probably heard the phrase “trusted execution environment” or “TEE.” It’s the hardware-backed trick that keeps data encrypted even while the CPU is working on it. I’ve spent enough time reading patent filings around this to realize it isn’t just a buzzword, it’s a genuine shift in how we think about trust in the cloud.
The Encrypted Brain Inside Your Server
The easiest way to picture confidential computing is to imagine a black box inside the processor. You put encrypted data and encrypted code into that box. The box locks itself, decrypts everything internally, processes it, encrypts the result, and only then lets the answer out. The operating system, the hypervisor, even the data center technician with physical access can’t see what’s happening inside. They see only opaque blobs.
Technologies like Intel SGX, AMD SEV-SNP, and ARM CCA make this work at the silicon level. They carve out a region of memory that is hardware-encrypted. The CPU keys are generated inside the processor and never leave. Some people call it “enclave computing” because you are creating a secure enclave in the middle of a potentially hostile environment.
Last year I came across a small startup that was building a tool for banks to jointly screen transactions for sanctions. Without confidential computing, they would have had to move all the data to a neutral third party’s database and hope for the best. With a TEE, the matching algorithm ran entirely inside the enclave. One bank’s raw data never touched the other bank’s raw data, and the cloud provider couldn’t sneak a peek either. That’s a practical trust revolution, not just a theory.
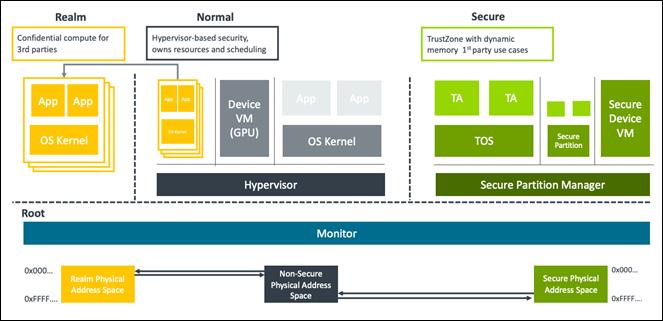
What a Basic Architecture Looks Like
I always find it easier to follow when I can see the moving parts. Here’s a simplified view of a confidential computing setup.
You need a few things to actually build a confidential computing environment. First, a Trusted Execution Environment is the core. That’s the hardware-level secure space. Hardware support is crucial. This isn’t something you can do in software alone. Modern CPUs from Intel (SGX), AMD (SEV), and ARM (TrustZone) have specific instructions and memory protections to create these enclaves.
Encryption is obviously there data stays encrypted throughout. But unlike traditional encryption, the keys are handled inside the enclave, so even the hypervisor or cloud provider doesn’t have access. Remote attestation is a less talked about but really important piece. It’s a way for you to verify that the code running inside the enclave is exactly what you expect, and hasn’t been tampered with. You can basically ask the hardware to prove the enclave is legitimate.
At the base, you have the cloud infrastructure you don’t fully trust. Sitting inside it is the enclave, which is a locked memory region. The application and its data enter encrypted. Before anything runs, an attestation handshake happens: the enclave generates a cryptographic quote proving it’s a genuine hardware enclave running unmodified code. A remote attestation service verifies that quote. Only if the check passes does the data decryption key get released to the enclave. The whole time, the cloud provider’s staff can’t access the plaintext.
This architecture changes the shared responsibility model. You no longer need to trust the cloud provider’s entire software stack. You still have to trust Intel or AMD to have built the hardware correctly, but that’s a far smaller circle.
Places It’s Quietly Making a Difference
Most headlines focus on confidential computing for financial services or healthcare, and that’s fair. But I’ve seen interesting use cases pop up in places that don’t make the evening news.
One is software IP protection. A company selling a machine-learning model to a factory can deliver it inside an enclave. The factory runs inference on their own sensitive production data, but they can’t extract the model weights. The seller’s intellectual property stays locked even while running on someone else’s hardware. That solves a huge licensing headache.
Another is in multi-party research. Pharmaceutical companies hate sharing raw compound data with competitors, but they do want to know if their molecules interact with similar protein targets. A confidential computing cluster can run simulations on pooled encrypted data and output only the interaction scores. No raw molecule structures get exposed.
Wearables and edge devices will likely follow. If my smartwatch could process heart rhythm anomalies in a small enclave and share only a verified alert with my doctor, I’d feel much better about privacy. The enclave could even prove mathematically that it followed the diagnostic algorithm exactly, without revealing raw waveform data.
Why It’s Not Yet Everywhere
Truthfully, confidential computing is still a bit fiddly. Performance overhead used to be punishing, though it has improved a lot. Enclave memory was tiny in the early Intel SGX days and trying to fit a large database index inside an enclave was like filling a suitcase with an elephant. You had to swap encrypted pages constantly, and that slowed things down. AMD’s SEV encrypts entire virtual machines with less pain, but you still need to benchmark your specific workload.
Attestation is another beast. Setting up a trustworthy attestation service and managing certificates across different clouds is no joke. And side-channel attacks, while highly sophisticated, are not science fiction. There’s a constant cat-and-mouse game between researchers and chip vendors.
Then there’s the human angle. If you write buggy code inside the enclave, the hardware will faithfully execute every vulnerability for you. The enclave isn’t a code reviewer. It just guarantees that no one outside can read the memory. Garbage code inside still produces garbage, or worse, leaks.
Where I Think It’s Headed
I suspect confidential computing will become boring in five years, which is the best compliment you can give a security technology. Cloud providers already offer it as a checkbox on certain VM types. Kubernetes operators for confidential containers are maturing. The Confidential Computing Consortium keeps pushing for open standards so that you can move an enclave workload across clouds without a rewrite.
The real magic will happen when confidential computing pairs with other privacy techniques and maybe combine it with federated learning so that local models share updates through an enclave that can’t snoop on individual contributions. That’s the kind of architecture that will finally make privacy regulations and innovative data sharing coexist without an endless legal battle.
For now, the idea that a server can process data it cannot read feels almost magical. But it’s real silicon and real code. It finally plugs that middle padlock. And for anyone thinking about the next generation of trustworthy computing, it’s the foundation we should be building on.
For a long time, protecting data at rest and in transit was considered good enough. But as we move toward more shared infrastructure and data-driven applications, the gap during processing has become too big to ignore. Confidential computing fills that gap. It lets you process sensitive data without exposing it is not even to the platform running it. That changes the trust model for cloud computing, multi-party analytics, and pretty much anything involving sensitive data in shared environments.
The technology is still maturing. Performance and usability need to improve. But I think it’s going to become a standard part of security architecture over the next few years, especially in regulated industries where data privacy isn’t optional.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.